https://www.mssqltips.com/sqlservertip/1020/enabling-xpcmdshell-in-sql-server/
If you have sysadmin privileges and don't enable xp_cmdshell and you issue a command such as the following
to get a directory listing of the C: drive:
you get the following error message:
Msg 15281, Level 16, State 1, Procedure xp_cmdshell, Line 1 [Batch Start Line 0]
SQL Server blocked access to procedure 'sys.xp_cmdshell' of component
'xp_cmdshell' because this component is turned off as part of the
security configuration for this server. A system administrator can
enable the use of 'xp_cmdshell' by using sp_configure. For more
information about enabling 'xp_cmdshell', search for 'xp_cmdshell' in
SQL Server Books Online.
If you don't have sysadmin privileges and try to run xp_cmdshell whether it
is enable or not you get this error message:
Msg 229, Level 14, State 5, Procedure xp_cmdshell, Line 1 [Batch Start Line 0]
The EXECUTE permission was denied on the object 'xp_cmdshell', database 'mssqlsystemresource', schema 'sys'.
Another error you may get if you try to enable xp_cmdshell using sp_configure when advanced
options is not set is the following error:
Msg 15123, Level 16, State 1, Procedure sp_configure, Line 62 [Batch Start Line 2]
The configuration option 'xp_cmdshell' does not exist, or it may be an advanced option.
So in order to use xp_cmdshell whether you are a sysadmin or a regular user
you need to first enable the use of xp_cmdshell.
Enable xp_cmdshell with sp_configure
The following code with enable xp_cmdshell using sp_configure. You need to
issue the RECONFIGURE command after each of these settings for it to take
effect.
-- this turns on advanced options and is needed to configure xp_cmdshell
sp_configure 'show advanced options', '1'
RECONFIGURE
-- this enables xp_cmdshell
sp_configure 'xp_cmdshell', '1'
RECONFIGURE
Disable xp_cmdshell with sp_configure
The following code with disable xp_cmdshell using sp_configure:
-- this turns on advanced options and is needed to configure xp_cmdshell
sp_configure 'show advanced options', '1'
RECONFIGURE
-- this disables xp_cmdshell
sp_configure 'xp_cmdshell', '0'
RECONFIGURE
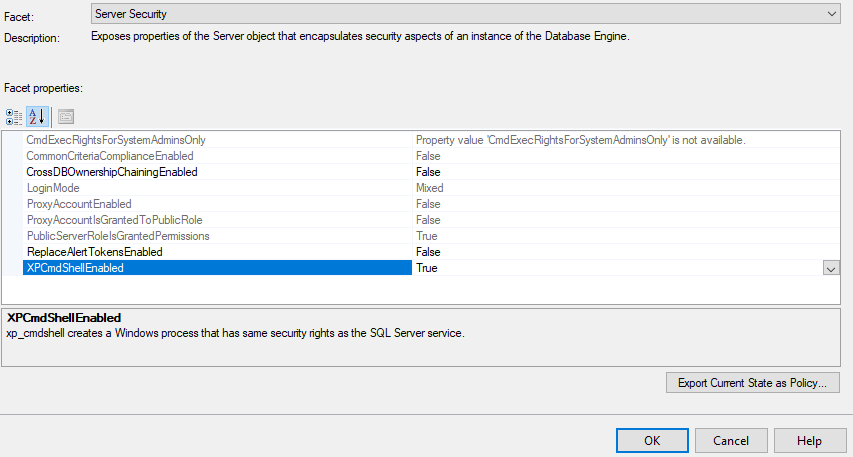
Enable or Disable xp_cmdshell with SSMS Facets
From within SSMS, right click on the instance name and select Facets.
The in the Facet drowdown, change to
Server Security as
shown below.
You can then change the setting for
XpCmdShellEnabled
as needed to either True or False. After changing the value, click OK to save the
setting and the change will take effect immediately. There is not a need
to enable show advanced options or use reconfigure, the GUI takes care of this
automatically.
Granting Access to xp_cmdshell
Let's say we have a user that is not a sysadmin, but is a user of the master
database and we want to grant access to run xp_cmdshell.
-- add user test to the master database
USE [master]
GO
CREATE USER [test] FOR LOGIN [test]
GO
-- grant execute access to xp_cmdshell
GRANT EXEC ON xp_cmdshell TO [test]
We get this error message:
Msg 15153, Level 16, State 1, Procedure xp_cmdshell, Line 1 [Batch Start Line 0]
The xp_cmdshell proxy account information cannot be retrieved or is
invalid. Verify that the '##xp_cmdshell_proxy_account##' credential
exists and contains valid information.
There is not a need to give a user sysadmin permissions or elevated
permissions to run xp_cmdshell. To do so you can create a proxy account as
shown in this tip
Creating a SQL Server proxy account to run xp_cmdshell.




 Here
is a small utility I made whose purpose is to flush (empty) the Windows
file cache. It can also flush and purge memory working sets, standby
and modified lists.
Here
is a small utility I made whose purpose is to flush (empty) the Windows
file cache. It can also flush and purge memory working sets, standby
and modified lists.