You read a lot of advice that says you shouldn’t shrink databases, but…why?
To demonstrate, I’m going to:
- Create a database
- Create a ~1GB table with 5M rows in it
- Put a clustered index on it, and check its fragmentation
- Look at my database’s empty space
- Shrink the database to get rid of the empty space
- And then see what happens next.
Here’s steps 1-3:
And here’s the output – I’ve taken the liberty of rearranging the output columns a little to make the screenshot easier to read on the web:

Near zero fragmentation – that’s good
We have 0.01% fragmentation, and 99.7% of each 8KB page is packed in solid with data. That’s great! When we scan this table, the pages will be in order, and chock full of tasty data, making for a quick scan.
Now, how much empty space do we have?
The results:

Our data file is 51% empty!
Well, that’s not good! Our 2,504MB data file has 1,277MB of free space in it, so it’s 51% empty! So let’s say we want to reclaim that space by shrinking the data file back down:
Let’s use DBCC SHRINKDATABASE to reclaim the empty space.
Run this command:
And it’ll reorganize the pages in the WorldOfHurt to leave just 1% free space. (You could even go with 0% if you want.) Then rerun the above free-space query again to see how the shrink worked:

Free space after the shrink
Woohoo! The data file is now down to 1,239MB, and only has 0.98% free space left. The log file is down to 24MB, too. All wine and roses, right?
But now check fragmentation.
Using the same query from earlier:
And the results:
After the shrink, 98% fragmented.
Suddenly, we have a new problem: our table is 98% fragmented. To do its work, SHRINKDATABASE goes to the end of the file, picks up pages there, and moves them to the first open available spaces in our data file. Remember how our object used to be perfectly in order? Well, now it’s in reverse order because SQL Server took the stuff at the end and put it at the beginning.
So what do you do to fix this? I’m going to hazard a guess that you have a nightly job set up to reorganize or rebuild indexes when they get heavily fragmented. In this case, with 98% fragmentation, I bet you’re going to want to rebuild that index.
Guess what happens when you rebuild the index?
SQL Server needs enough empty space in the database to build an entirely new copy of the index, so it’s going to:
- Grow the data file out
- Use that space to build the new copy of our index
- Drop the old copy of our index, leaving a bunch of unused space in the file
Let’s prove it – rebuild the index and check fragmentation:
Our index is now perfectly defragmented:
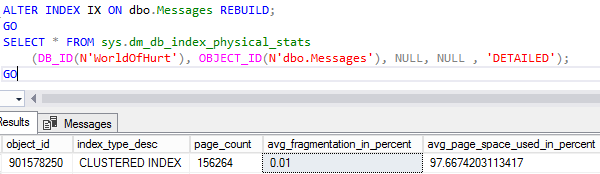
Perfectly defragmented
But we’re right back to having a bunch of free space in the database:

Back to 1.2GB of empty space in the data file
Shrinking databases and rebuilding indexes is a vicious cycle.
You have high fragmentation, so you rebuild your indexes.
Which leaves a lot of empty space around, so you shrink your database.
Which causes high fragmentation, so you rebuild your indexes, which grows the databases right back out and leaves empty space again, and the cycle keeps perpetuating itself.
Break the cycle. Stop doing things that cause performance problems rather than fixing ’em. If your databases have some empty space in ’em, that’s fine – SQL Server will probably need that space again for regular operations like index rebuilds.
If you still think you want to shrink a database, check out how to shrink a database in 4 easy steps.
Erik Says: Sure, you can tell your rebuild to sort in tempdb, but considering one of our most popular posts is about shrinking tempdb, you’re not doing much better in that department either.
25 . Leave new
-
I completely agree that regularly shrinking databases (or to be more specific, data files) is a very bad thing. It is very resource intensive and it creates severe index fragmentation. We’ll leave aside your previous guidance that index fragmentation does matter at all and that all index maintenance is a counter-productive waste of time.One valid reason to specifically shrink a data file would be if you had deleted a large amount of data that was not coming back any time soon (or ever) and/or you had dropped many unused large indexes, such that you had a quite large amount of free spaces in your data file(s).If this were the case, and if you were low on disk space on the LUNs where the data file(s) were located (and you could not easily grow the LUNs), then I might want to go ahead and shrink the data file(s) with DBCC SHRINKFILE commands, as a one-time operation.This would still be resource intensive, and would still cause severe index fragmentation, but I would have less concurrent impact to system than using DBCC SHRINKDATABASE (I would shrink the log file later, in a separate operation).After the DBCC SHRINKFILE operations were done, I would use ALTER INDEX REORGANIZE to reduce the index fragmentation without growing the data file(s) again. Simply using REORGANIZE rather than REBUILD avoids the vicious circle of shrinking and growing that your demo illustrates.ALTER INDEX IX ON dbo.Messages REORGANIZE;Finally, if necessary, I would shrink the log file, and then explicitly grow it in relatively large chunks to my desired size, to keep the VLF count low.So, I would never use DBCC SHRINKDATABASE. Instead, I would use DBCC SHRINKFILE only in special circumstances, and in a targeted manner, never as part of some automated, nightly process.
No comments:
Post a Comment
Note: only a member of this blog may post a comment.